Note: This is a tactical follow-up to Stop Treating Your LLM Like a Magic Wand. That post was about methodology-plan and verify instead of vomit-and-pray. This one is narrower and about money: how teams quietly burn tokens redoing work they already solved. It's part of my AI implementation consulting.
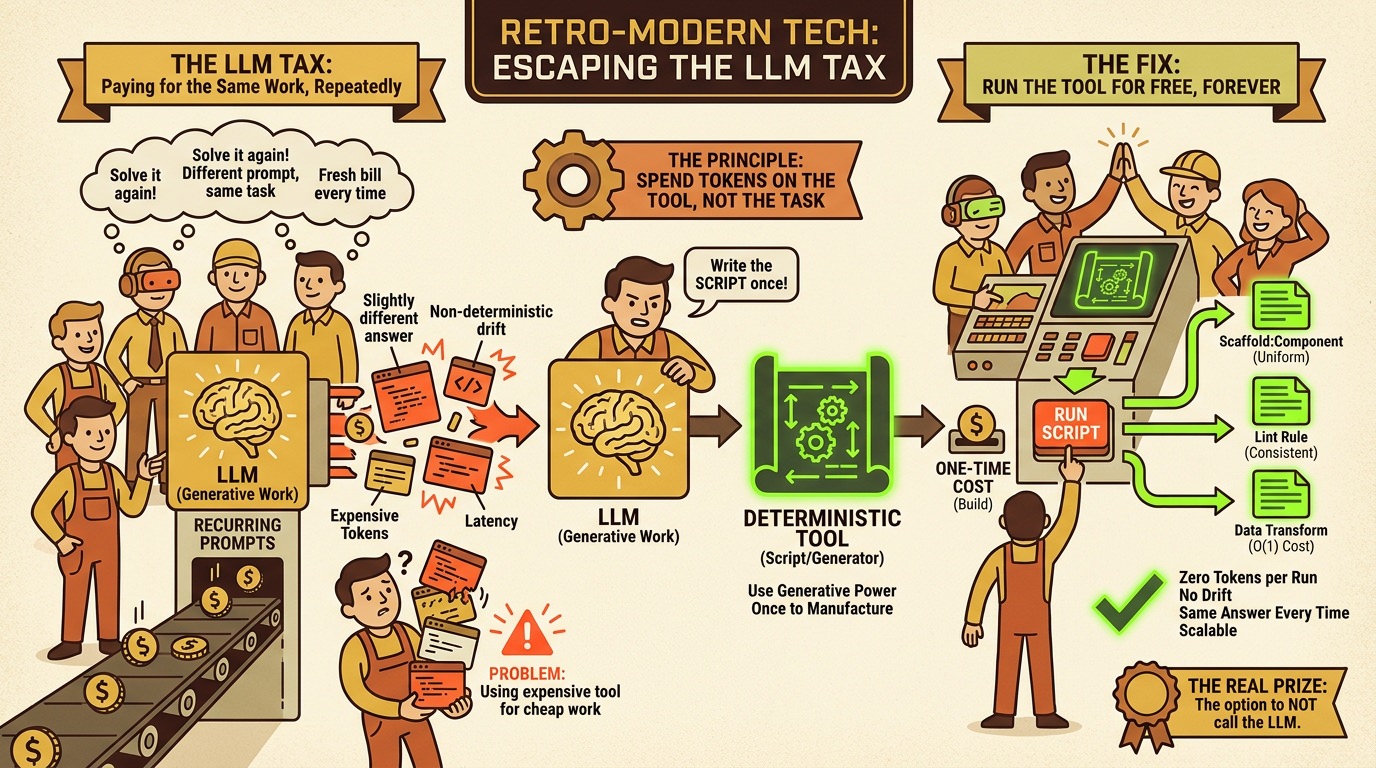
Here's a pattern I see in almost every team that adopts LLMs seriously: they solve a problem once, beautifully, with the model. Then they solve it again next week. And again the week after. Same task, same prompt, fresh bill every time.
That's the LLM tax. You're paying-in tokens, in latency, and in non-determinism-for work you already figured out.
And the token bill is the cheap part. The expensive part is the one nobody puts on a dashboard: ten engineers each inventing their own way to work with AI-different cost, different quality, no shared standard-and a codebase that quietly shows it. The waste you can measure is a rounding error next to the waste you can't. Fix the measurable kind first; it's the thread that unravels the rest.
The fix is boring, which is exactly why people skip it: use the LLM once to write a script, then run the script forever.
Two kinds of work, and the mistake that mixes them
There are two kinds of work in front of you:
- Generative work needs judgment. Design a schema. Untangle a confusing bug. Decide how a feature should behave. This is where a model earns its tokens-it's novel, it's fuzzy, it's worth paying for.
- Deterministic work has one right answer and you do it the same way every time. Open a PR. Scaffold a component. Convert a CSV. Rename a symbol across the repo.
The mistake is using the expensive, metered, non-deterministic tool to do the cheap, free, deterministic work. An LLM call costs money and gives you a slightly different answer each time. A script costs nothing and gives you the same answer every time. When you re-prompt for a procedure you've already solved, you pay twice: once in tokens, once in the risk that this run is the one that quietly gets it wrong.
The principle is one line:
Spend tokens on the tool, not the task.
Use the model's generative power once to manufacture a deterministic tool. Then run the tool for free, as many times as you want, with the same result every time. Your LLM should write the script-not be the script.
Here's where that plays out.
1. Stop bolting on an MCP server for something a CLI already does
The reflex right now is "there's a task involving GitHub, so wire up the GitHub MCP server." Then every session pays for it.
❌ Every task pays the MCP tax:
- The MCP server loads its full tool schema into context on every session
- Every "open a PR" round-trips through the model
- You're spending tokens to re-derive a flow you've run a hundred times
The gh CLI already does this, deterministically, for free:
✅ Let the model write the command once-then it's just a command:
gh pr create --base dev --title "fix(api): handle null tenant" \
--label "ready-for-review" --reviewer alice
# Better: wrap the whole recurring flow into a script
bash scripts/open-pr.sh "fix(api): handle null tenant"
Now opening a PR with your labels, your base branch, your reviewers, and your templated body is a single cheap trigger instead of a flow the model re-derives every time-and it never drifts. The model's job was to write open-pr.sh one time. After that, it's plumbing. (Does triggering it still cost a few tokens? Yes-a small, fixed amount that doesn't grow with the work. I break down the exact accounting below.)
This isn't anti-MCP. MCP is great when you genuinely need the model in the loop making decisions. It's wasteful when you're using it as an expensive remote control for a deterministic command.
2. Scaffold components, don't regenerate them
"Create a new Button component following our patterns" feels productive. It's one of the most expensive habits you can have.
❌ "Create a new Button component following our patterns"
→ regenerated from scratch every single time
→ subtly different structure on each run
→ this one's missing the barrel export
→ that one forgot the test
→ the next one named the props type differently
Every regeneration is tokens plus drift. The model isn't a stencil; it improvises. Five components generated five times are five slightly different components.
A generator is a stencil:
✅ bun scaffold:component Button
→ file + test + story + barrel export
→ byte-for-byte consistent with the canonical pattern
→ zero tokens, zero drift
And here's the part people miss: once it's a script, the developer can run it. You don't need the LLM at all anymore. You spent the model's judgment once-on encoding the pattern into a generator-and now a junior dev, a CI job, or you at 2am all produce the exact same correct output. That's the whole game: convert a thing you'd otherwise ask for repeatedly into a thing nobody has to ask for.
3. Don't make the model the runtime
This is the one that hurts the bill the most. Someone pastes 2,000 rows of CSV into the chat and asks the model to "convert these to JSON and normalize the dates."
❌ [paste 2,000 rows] "convert these to JSON and normalize the dates"
→ token cost scales with the number of rows
→ you got back "probably" all of them, in the right format, maybe
→ next quarter's file? Pay the whole bill again.
The model should never be the thing processing the data. It should be the thing that writes the thing that processes the data:
✅ "Write a script that reads rows.csv, converts to JSON, and normalizes the dates"
→ run it on 2,000 rows or 2,000,000-the model's cost is the same flat trigger
→ deterministic, testable, and still there next quarter
Rule of thumb: if the data has more than a handful of rows, the LLM writes the transform, it doesn't be the transform. Using a billion-parameter model as a hand-cranked for loop is the most expensive way to iterate ever invented.
4. Codemods over hand-edits
"Rename useAuth to useSession everywhere" across 80 files.
❌ The model opens and edits all 80 files
→ 80x the tokens
→ 80x the chance of a quiet slip in file 57 that you won't notice until prod
→ a diff so large nobody actually reviews it
✅ "Write an ast-grep (or codemod) rule that renames useAuth to useSession"
→ one transform you can actually read and reason about
→ applied atomically across the whole repo
→ reversible, re-runnable, and reviewable in 30 seconds
One reviewable rule beats 80 hopeful edits. And if it's wrong, it's wrong consistently, which is far easier to spot and fix than a single silent miss buried in a giant diff.
5. Turn "review this for X" into a lint rule
If you find yourself asking the model to "check this PR for direct createClient() calls" or "make sure nobody imported from server/ in client code"-every PR, forever-you're renting an answer you should own.
❌ "Review this PR for direct createClient() calls" ← every PR, indefinitely
✅ The model writes the Biome/ESLint/grep rule once ← CI enforces it for everyone, free
This one has a bonus: it solves consistency. A prompt protects one PR, when someone remembers to run it. A lint rule protects every PR from every developer, automatically. You've converted a per-request token cost into a permanent, zero-cost guardrail-and made the standard the same for the whole team instead of "whatever each person remembered to ask."
Hold on-doesn't running the script still cost tokens?
Yes. Let's be precise, because I've been loose with the word "free" up to here.
When a human or CI runs the script, it's genuinely zero-there's no model in the loop at all. But when the assistant runs it for you, you do pay tokens. Just not many, and-this is the entire point-not in proportion to the work.
Here's everything the model spends to invoke a script:
- emit the command ~tens of tokens ("bash scripts/convert.sh")
- read the result back however much the script prints
- reason over the result small
(the skill + system prompt are re-sent each turn, but prompt-cached)
What's missing from that list is the expensive part: tokens proportional to the size of the job. Doing the work inside the model costs O(N)-2,000 rows in, 2,000 rows out, every one of them passing through the context window. Triggering a script costs O(1)-the same flat handful of tokens whether the script then touches 2,000 rows or 2,000,000.
Here are the three ways that same task can run, and what each one actually costs:
| AI does the work | AI invokes a script | Dev / CI runs it | |
|---|---|---|---|
| Who actually does it | the model, token by token | the script; the model just triggers it | the script |
| Token cost | O(N), scales with the job | O(1), a small fixed trigger | zero, no model in the loop |
| A 2,000,000-row job | pay for every row | a few tokens | nothing |
| Output | non-deterministic, varies run to run | deterministic | deterministic |
| Reach for it when | the task is novel, one-off, or needs judgment | it recurs but you still drive it from a chat or agent | it's known, repeated, and needs no judgment |
The whole game is pushing work to the right: out of column 1, where you pay per unit of work and the answer wobbles, into columns 2 and 3, where the cost flattens and the output is identical every time.
So "free" was shorthand. The honest version: invoking a script turns a cost that scales with the work into a small, fixed cost that doesn't. And if you want actual zero, take the model out of the loop entirely and let the dev or CI run it. That's the real prize the scripts-plus-skills setup buys you-the option to not call the LLM at all.
The tip: don't let the script dump its output back into context
There's one easy way to throw all of this away. If the script prints its whole payload to stdout, the assistant has to read that payload back in as the tool result-and you've quietly re-paid the exact O(N) cost you were trying to dodge.
❌ The script prints all 2,000,000 converted rows to stdout
→ the model ingests every row as the tool result
→ congratulations, you paid O(N) tokens anyway-the script bought you nothing
✅ The script writes to a file and prints a one-line summary
→ "✓ converted 2,000,000 rows → out.json (12.4 MB)"
→ the model reads one line; the cost stays O(1) no matter how big the job
So when you have the model write a script for a big job, tell it explicitly: write the result to a file, and print only a short summary. The assistant needs to know the script succeeded-it doesn't need to see the output. Same rule for anything noisy: pipe verbose logs to a file and surface a single status line. Keep what comes back into context small, and the trigger stays cheap.
A script nobody knows about doesn't get run
Here's the failure mode that kills this whole approach in practice: you build the scripts, and then half the team never finds out they exist. A new hire reaches for the LLM and re-prompts a flow from scratch. A senior dev who wasn't in the room when scaffold:component was written quietly writes a sixth, slightly different version. The tooling is there, sitting in scripts/, getting ignored.
A script you have to remember is a script you'll forget. So don't make discovery the developer's job-make it the assistant's.
This is what skills are for. A skill is a small, named instruction that teaches your AI assistant when to reach for a specific tool and how to use it. You write it once, hand it to the team, and now the assistant itself becomes the dispatcher:
✅ A "scaffolding" skill, loaded into every dev's assistant:
When the user wants a new component, route, or lib:
→ run `bun scaffold:component <Name>` — do NOT hand-write it
→ the generator produces the file, test, story, and barrel export
When the user wants to open a PR:
→ run `bash scripts/open-pr.sh "<title>"` — it sets our base,
labels, reviewers, and templated body
Now a developer who has never heard of scaffold:component still gets it-because their assistant knows, and reaches for it on their behalf. The dev asks for the outcome ("I need a new Button component"); the skill routes them to the deterministic tool instead of letting the model freehand a one-off. They didn't need to know the toolbox existed. The assistant knew for them.
That's the part that makes this enforceable instead of merely available:
- Onboarding collapses to zero. A new hire on day one gets the same correct behavior as your most senior engineer, because they're handed the same skills. You're not relying on docs nobody reads or a perfect onboarding checklist-the standard lives where the work actually happens.
- The default path is the right path. When the assistant defaults to your scripts, doing it the wrong way (re-prompting, hand-rolling, drifting) becomes the thing you have to go out of your way to do.
- You update one place, everyone gets it. Change the script, update the skill, and the whole team's assistants are on the new behavior the next time they work-no all-hands memo, no "hey did you see the new generator" in Slack.
So the full chain is: the model writes the script once, the script becomes the deterministic tool, and the skill makes sure the tool actually gets used-by people who don't even know it's there. Tokens spent once, correctness distributed to everyone, forever.
The litmus test
You don't need a framework for this. One question:
If I'd be annoyed asking a human colleague to do this by hand more than twice, it should be a script-and the LLM's job is to write the script, not to keep being it.
Repeated? Deterministic? Same shape every time? That's a script. Pay the model once to write it.
When NOT to do this
Scripts aren't free either-they cost maintenance, and a generator for something you'll do exactly once is its own kind of waste. So don't get religious about it.
Keep paying for the model where it actually earns it:
- Genuinely novel work. First time you're solving something, you don't know the shape yet. Let the model help you find it.
- One-shot tasks. A migration you'll run a single time doesn't need a polished generator. Just do it.
- Judgment-heavy work. Architecture, debugging, naming, deciding behavior. There's no deterministic script for "is this the right design." That's exactly what the tokens are for.
The waste isn't using the LLM. The waste is using it as a human-powered for loop for work that has one right answer.
The bottom line
Use the model to build the machine, not to hand-make each part.
Every recurring prompt in your workflow is a script you haven't written yet. Find the ones that are deterministic and repeated, spend the model's tokens once to turn them into tooling, and then run that tooling for free until the end of time. Your bill goes down, your output stops drifting, and-this is the underrated part-the work stops needing the LLM at all. Anyone on the team can run a script.
The cheapest token is the one you never spend.
If your team has adopted AI but every developer uses it differently-different costs, different quality, no shared discipline-that's the real problem, and it's bigger than any token bill. Installing that discipline across an engineering org, so the right way is the default way, is the work I do. .
References
- Stop Treating Your LLM Like a Magic Wand - the methodology this builds on
- Building Effective Agents - Anthropic Research, on workflows vs. agents and choosing the right system
- GitHub CLI (
gh) - the deterministic tool you probably already have installed - ast-grep - structural search and codemods for writing your own transforms